
AI & Security
AI for Security
사이버보안을 발전시키기 위한 수단 중 하나로 AI가 쓰이는 경우.
탐지, 예방, 대응하는 과정에서 AI를 사용하여 악성코드와 공격을 잡게 된다.
발전하고 있는 AI의 기술을 사용해서 사이버보안을 확립한다.
Security for AI
AI에서 나타날 수 있는 사이버보안에 대해 연구.
AI 또한 사이버보안과 관련된 이슈들에 노출될 수 있기 때문이다.
(e.g., adversarial attacks, data poisoning, model inversion, model stealing, etc.)
논문: 《Android Malware Detection》
Android Malware Detection
① 경량 분석: 스마트폰에서 악성 소프트웨어를 효율적으로 감지하고, 큰 규모의 애플리케이션 집합을 합리적인 시간 내에 분석한다.
② 효과적인 감지: 수작업으로 제작된 감지 패턴에 의존하지 않고 높은 정확도와 낮은 오탐률을 유지한다.
③ 설명 가능한 결과: 감지된 악성 소프트웨어의 인스턴스를 나타내는 특징 패턴을 제공한다.
System Overview
정적 분석을 통해 여러가지 feature들을 뽑아내고, 이를 벡터화 시킨 뒤 학습을 시켜서 그 결과를 통해 악성코드를 설명하게 된다.

Static Analysis (1)
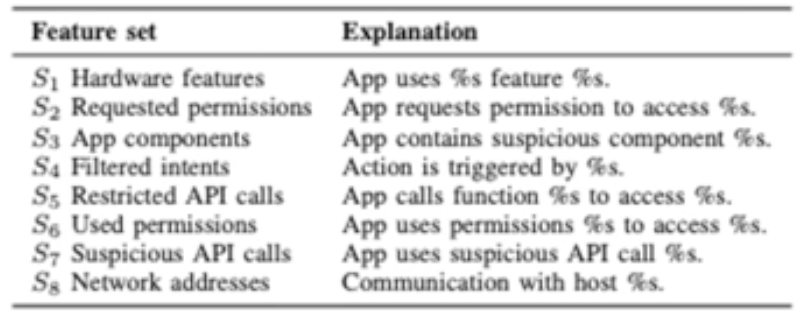
어플리케이션에 존재하는 매니페스트 파일을 통해서 얻을 수 있는 정적 분석의 Feature sets
• Hardware Components (S1)
- 애플리케이션이 스마트폰의 카메라, 터치스크린 또는 GPS 모듈에 대한 접근을 요청하는 경우, 이러한 기능들은 매니페스트 파일에 선언되어야 한다.
- 특정 하드웨어에 대한 접근 요청은 분명히 보안상의 영향을 미치며, 특정 하드웨어 조합의 사용은 종종 해로운 행동을 반영한다.
• Requested Permissions (S2)
- 설치 시 사용자에 의해 적극적으로 부여되며 애플리케이션이 보안과 관련된 리소스에 접근할 수 있게 한다.
- 악성 소프트웨어는 무해한 애플리케이션보다 특정 권한을 더 자주 요청하는 경향이 있다.
• App Components (S3)
- 애플리케이션에는 네 가지 다른 유형의 구성 요소가 있으며, 각각 시스템에 대한 다른 인터페이스를 정의한다: activities, services, content providers, broadcast receivers.
- 각 애플리케이션은 매니페스트에 각 유형의 여러 구성 요소를 선언할 수 있다 (악성 소프트웨어의 잘 알려진 구성 요소).
• Filtered Intents (S4)
- 안드로이드에서 프로세스 간 및 프로세스 내 통신은 주로 인텐트를 통해 수행된다.
- 인텐트는 비동기 메시지로 교환되는 수동 데이터 구조로, 서로 다른 구성 요소 및 애플리케이션 간에 이벤트에 대한 정보를 공유할 수 있게 한다.
Static Analysis (2)
바이트 코드를 Reverse engineering을 통해 disassembling으로 소스코드를 복원했을 때 나오는 Feature sets
• Restricted API Calls (S5)
- 안드로이드 권한 시스템은 일련의 중요한 API 호출에 대한 접근을 제한한다.
- 악성 행위를 드러내는 특정 사례는 필요한 권한을 요청하지 않은 제한된 중요 API Call의 사용이다.
• Used Permissions (S6)
- S5에서 추출된 전체 호출 집합은 요청된 권한과 실제로 사용된 권한의 하위 집합을 결정하는 기준으로 사용된다.
- 사용되는/되지 않는 Permission들을 구분한다.
• Suspicious API Calls (S7)
- 특정 API 호출은 스마트폰의 민감한 데이터나 리소스에 접근할 수 있으며, 악성 소프트웨어 샘플에서 자주 발견된다.
- 이러한 호출은 특히 악성 행위로 이어질 수 있으므로, 별도의 특징 세트로 추출되고 수집된다.
- 다음은 suspicious API의 5가지 종류이다.
① accessing sensitive data: getDeviceld(), getSubscriberld()
② network communication: execHttpRequest(), setWifiEnabled()
③ sending and receiving SMS messages: sendTextMessage()
④ execution of external commands: Runtime.exec()
⑤ frequently used for obfuscation: Cipher.getInstance()
• Network Addresses (S8)
- 악성 소프트웨어는 정기적으로 네트워크 연결을 설정하여 장치에서 수집된 데이터를 검색하거나 유출한다.
- 따라서, disassembled 코드에서 발견된 모든 IP 주소, 호스트 이름 및 URL은 마지막 특징 세트에 포함된다.
Embedding in Vector Space (벡터 임베딩)
위의 8가지 feature들을 통해 serialization, 직렬화를 시켜 하나의 벡터처럼 다루게 되었다.

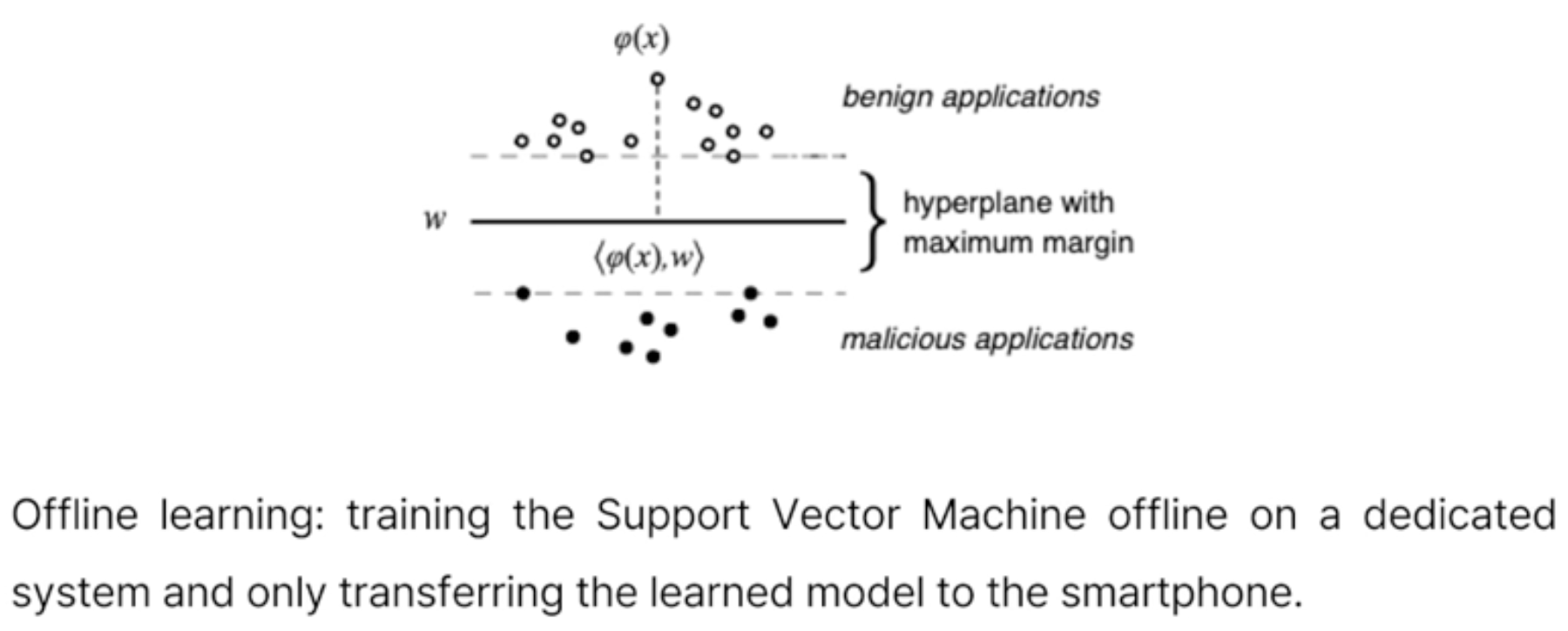
• 벡터들을 통해 Support Vector Machine 분류 기법으로 모델링하였다.
• 악성을 포함하지 않은 양성 코드 벡터들(benign applications)의 위치, 악성 코드 벡터들(malicious applications)의 위치가 다음과 같은 때 둘 사이의 거리를 최대로(maximum margin) 만들 수 있는 support vector를 만든다.
• 학습 자체가 스마트폰에서 일어날 경우, 부족한 리소스로 인해 Offline learning을 통해 malware dectection을 수행했다.
Explanation
• 실제로 감지 시스템은 악성 활동을 보고하는 것뿐만 아니라 감지 결과에 대한 설명을 제공해야 한다.
• 이는 블랙박스 학습 기반 접근법의 일반적인 단점이다.
• 설명 가능한 감지는 연구자들이 악성 소프트웨어의 패턴을 검토하고 기능에 대한 깊은 이해를 얻는 데 도움을 줄 수도 있다.
• 특정한 어플리케이션의 벡터가 계산되는 과정에서, 벡터의 위치에 영향을 미치는 가장 큰 weight를 가지는 것을 계산하게 된다면, 계산 결과에 영향을 미친 feature들을 순서대로 매길 수 있다는 것이다.

Evaluation
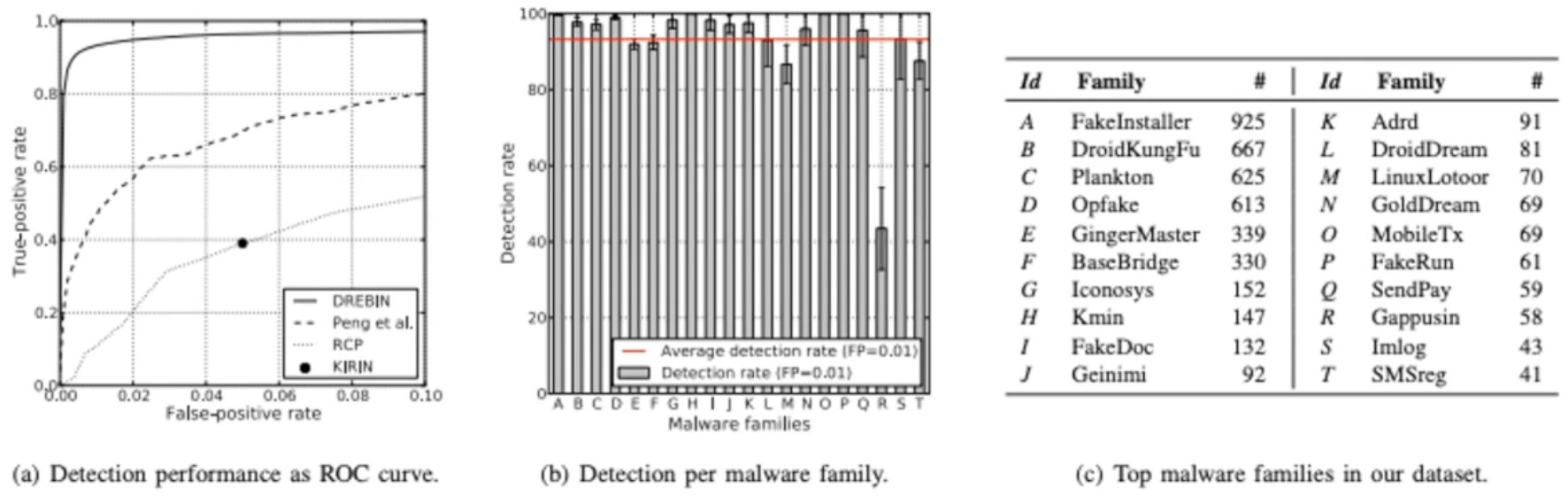
• 한 데이터셋은 실제 안드로이드 애플리케이션과 실제 악성 소프트웨어로 구성된다. 특히, 초기 데이터셋은 131,611개의 애플리케이션으로 구성되어 있으며, 이 중에는 양성 및 악성 소프트웨어가 포함되어 있다.
• 최종 데이터셋에는 123,453개의 양성 애플리케이션과 5,560개의 악성 샘플이 포함되어 있다.

Evaluation (Accuracies and Families)
FP가 높다면, 굉장히 관대하게 판단한다는 뜻이다. 즉, 악성이라고 판단하는 경우가 많다는 의미이다.
Evaluation (Unknown Families)
무작위 악성코드 샘플을 넣었을 경우에도, 10개 이상의 샘플만 주어진다면 그 뒤로는 악성코드에 대한 정확도가 높아졌다.

Evaluation (Features by Families)

Evaluation (Dominant Features)
거의 모든 family에 대해서 S2가 가장 높은 dominant한 feature를 보이게 된다.
그 외에도 API Calls 단계가 유니크한(악성코드와 양성코드가 분리되는) feature들을 가지고 있다.

Evaluation (Performance)

Takeaway
• 요약: ML / AI를 사용하여 안드로이드 내에 있는 악성코드를 검출하는 시스템
• 논문 자체는 오래되었지만, 다양한 감지 시스템에 머신 러닝(ML) 및 인공 지능(AI) 기술을 적용한 연구들을 배울 수 있다.
• 이를 통해 악성 트래픽, 침입 탐지, 피싱 감지 등 다른 도메인에 적용할 수 있는 ML/AI 기반 시스템의 평가 방법을 학습할 수 있다.
논문: 《Trojaning Attack on Neural Networks》
Neural Networks
• 신경망은 널리 채택되었다.
• 시간, 데이터, 또는 모델을 처음부터 훈련시키는 부족으로 인해 모델 공유와 재사용이 매우 인기 있다.
• Mozilla DeepSpeech는 2개월 내에 16,000회 이상 다운로드를 경험했다.
• Bigmi, Openml, Gradientzoo 등의 플랫폼들이 있다.
Model Sharing

Model Trojan
• 주어지는 인풋 데이터에 대해 특정한 trigger를 넣어 놓는 것만으로 딥러닝 모델이 잘못된 결과를 도출하도록 만든다.
• 이미지에서 어떤 부분을 바꿨을 때, 텐서가 반응하는 지를 알아내게 된다면(텐서가 아웃풋을 낼 때 어떤 역할을 하는가) 의도된 classification 결과를 이끌어낼 수 있다.

Gradient Descent
• Gradient descent는 머신 러닝에서 사용되는 최적화 알고리즘으로, 일반적으로 손실 함수를 최소화하기 위해 매개변수를 가파른 경사의 방향으로 반복적으로 조정한다.
• θ:=θ−α∇J(θ)θ:=θ−α∇J(θ) 여기서,
- αα: 학습률 (Learning rate)
- ∇J(θ)∇J(θ): 손실 함수의 그래디언트 (Loss function gradient)
• 이 알고리즘은 모델의 정확도와 일반화 능력을 향상시키는 데 사용된다.
Tigger Generation
• 우리는 트리거를 생성하는 방식으로, 트리거가 일부 내부 뉴런에서 높은 활성화를 유발할 수 있도록 한다.
• 은닉층은 은밀함을 유발한다.
• 트로이 목마 트리거의 모양, 위치, 투명도는 모두 구성 가능하다 (패턴, 픽셀, 패치, 워터마크 등).
Training Data Generation
• 우리는 출력 뉴런을 높은 활성화로 유도할 수 있는 입력을 생성한다.
• 이러한 이미지들은 해당 뉴런에 의해 나타내지는 데이터로 볼 수 있다.
• 두 가지 종류의 훈련 데이터는 트로이 목마 행동을 주입하고 여전히 양성 능력을 포함하고 있다.


Evaluation Setup
• 5 neural network applications from 5 different categories (Face Recognition, Speech Recognition, Age Recognition, Natural Language Processing, and Autonomous Driving).
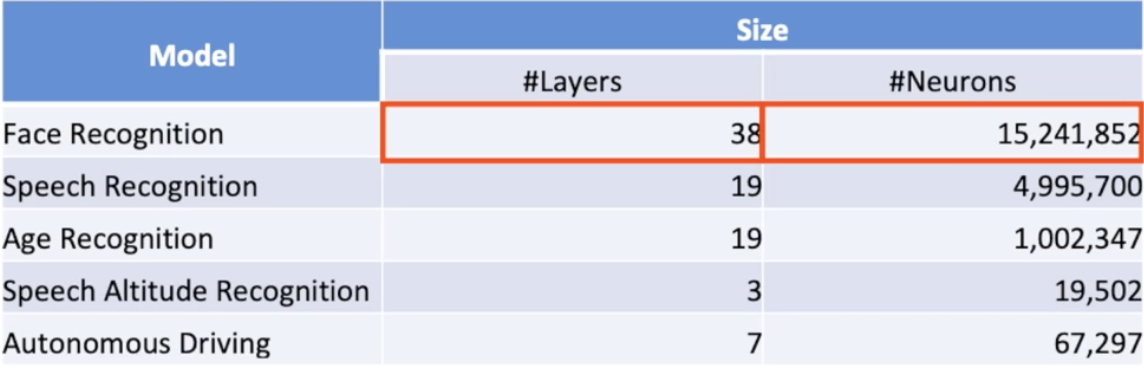
Effectiveness
딥러닝 모델이 공격을 당했다고 하더라도, 대부분 정확하게 판단한다. 다만, 매우 특수한 조건이 있을 때만 오작동을 하게 된다.

Efficiency
Trojan Attack을 통해 딥러닝 모델이 오작동을 일으키도록 만들 수 있다.

Takeaway
• 딥 러닝 모델에 대한 트로이 목마 공격은 이제 일반적으로 "Backdoor Attack(백도어 공격)"이라고 불린다.
• 이 논문은 적절한 도메인 선택과 논문의 내용을 구축하는 것이 얼마나 중요한지를 보여준다.
'Cyber Security' 카테고리의 다른 글
| [ATCS] Software Supply Chain Security (4) | 2024.07.14 |
|---|---|
| [ATCS] Network Security (1) | 2024.07.14 |
| [ATCS] Security and Forensics Techniques (2) | 2024.07.13 |
| [ATCS] Security Basics (3) | 2024.07.13 |