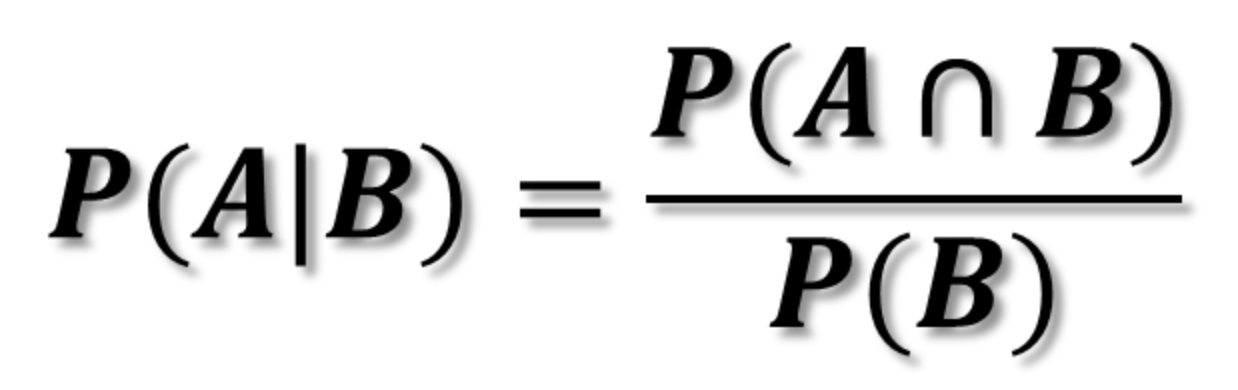다음을 보면, 영어의 성격을 고려해서 복잡성의 정도에 따라 도식화를 통해 분석할 수 있다.
복잡성의 정도에 따라 네 가지 기준을 설정하면, 하나의 텍스트를 네 가지의 다른 방식으로 분석할 수 있다 품사 < 통사구조 < 개체 간 관계 < 술어
따라서, 위 이미지에서 아래쪽에 위치할 수록 문장이 함의하고 있는 메시지를 더 잘 설명해주고 복잡성은 높아진다.
말뭉치(corpus)와 토큰화(tokenization)
· 말뭉치: 언어 연구를 위해 텍스트를 컴퓨터가 읽을 수 있는 형태로 모아 놓은 언어 자료. 처리하고 분석할 자연어 자체. · 토큰화: 말뭉치를 분석하기 위해 작은 단위인 토큰(token)으로 쪼개는 과정. 단위의 기준은 상황 별로 달라지며, 한국어의 경우 어절 토큰화, 단어 토큰화, 형태소 토큰화 등 단위가 다양하다.
불용어(stop words)
'the'나 'of'와 같이 문장에 자주 등장하며 중요한 문법적 기능을 수행하지만, 실질적인 의미를 전달해주지는 못하는 단어
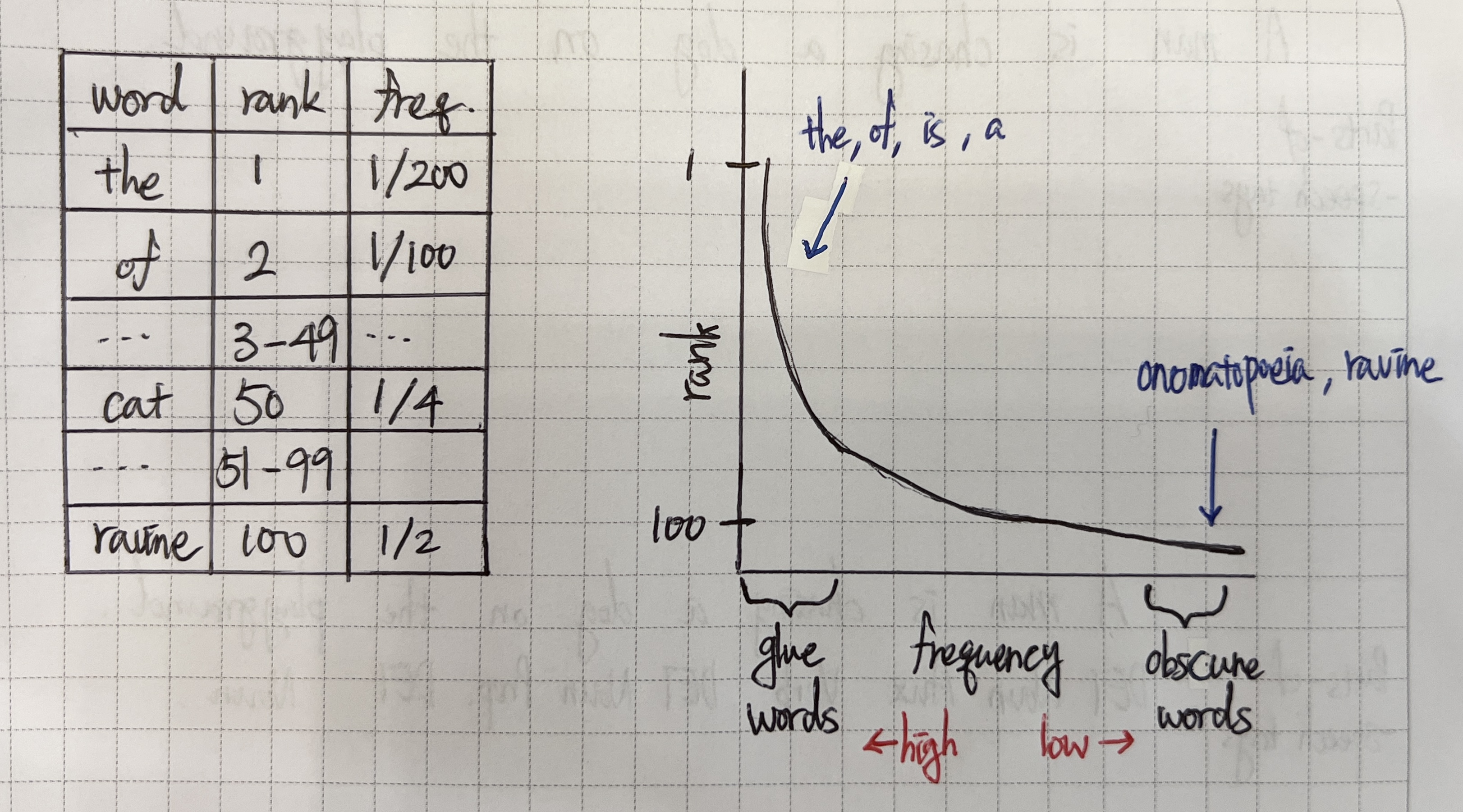
양극단에 위치한 단어들은 단순히 문법적 기능만을 수행하거나('the', 'of', 'is', 'a', etc.) 지나치게 어려운 단어('onomatopoeia')이다. 자연어 처리에서는 특히 전자의 단어들에 주의가 필요하다. 문장에 자주 출현하지만 중요한 의미를 지니지 않기 때문이다. 실제로 Zipf's Law에 따르면 사용 빈도가 매우 높은 단어의 경우 주로 문법적 기능을 수행하는 짧은 단어가 된다는 경향성이 존재한다.
◆ Zipf's Law(지프의 법칙): 사용빈도가 가장 높은 단어는 짧은 단어가 된다는 경향성.
자연어 처리에서는 텍스트 분석 시 불용어를 적절히 필터링하여 좋은 단어, 즉 문서의 중요한 의미를 잘 전달하는 단어를 중심으로 분석을 진행해야 한다.
대표적인 한국어의 불용어 예시
품사 태그
형태소 수
형태소 목록
IC(감탄사)
33
그래, 아니, 아, 뭐, 응, 네, 예, 자, 야, 글쎄, 참, etc.
NNB(의존 명사)
136
것, 수, 등, 년, 때문, 일, 중, 월, 씨, 데, 번, 명, etc.
MM(관형사)
64
그, 이, 한, 두, 다른, 그런, 이런, 어떤, 모든, 몇, 어느, etc.
...
...
...
인코딩(encodings)
텍스트 문서를 숫자로 표현하는 작업
텍스트를 숫자로 표현해야 하는 이유는? · 컴퓨터는 텍스트가 아닌 숫자 형식을 읽을 수 있기 때문 ·텍스트 문서를 정량적(quantitative)으로 분석한 후 분석에 대한 결론은 정성적(qualitative)으로 내릴 수 있는 장점
n-gram 모델
조건부 확률
자연어를 분석할 때 각 단어의 배열 순서를 고려하는 것은 중요하다. n-gram 언어 모델은 단어의 배열 순서를 고려하는 모델이다.
문장을 여러 단어의 '합'이라 본다면, 문장 내의 여러 단어가 어떠한 순서로 배열되는 지에 따라 문장을 확률값으로 표현할 수 있다.
확률을 통해 앞선 단어 조합을 바탕으로 '그 다음 단어에 무엇이 올 지' 예측할 수 있다.
Example 'the', 'black', 'cat'이라는 세 단어의 가정. 세 단어를 배열하는 순서에 대한 다양한 경우의 수가 있고, 각 경우가 발생할 확률값이 존재할 것이다.
'the black cat'의 순서로 배열될 확률 = [세 단어 중 the가 첫째로 선택될 확률] x [the 다음 단어로 black이 선택될 확률] x [the와 black 다음 단어로 cat이 선택될 확률]
위의 예시와 같이 세 개 확률값의 곱으로 나타낼 수 있다. 이때 "the black cat"이 "the cat black"보다 자연스럽게 느껴지는데, 실제로 확률을 계산해보면 전자가 후자보다 확률값이 높다.
① 조건부 확률 사건 B가 일어났을 때 사건 A가 일어날 조건부 확률② 확률의 곱셈법칙 : 교집합을 조건부확률의 곱으로 나타낸 것 사건이 두 개일 때, P(A, B) = P(A)P(B|A) = P(B)P(A|B) 사건이 세 개일 때, P(A, B, C) = P(AB)P(C|AB) = P(A)P(B|A)P(C|AB) 사건이 n개일 때, P(E_1, E_2, E_3, ..., E_n) = P(E_1)P(E_2|E_1)P(E_3|E_1, E_2) ... P(E_n|E_1, ..., E_n-1)
만약 한 문장이 총 T개의 단어로 구성되어 있다고 하면, 문장의 단어 배열 순서를 나타내는 확률은 아래 수식과 같다. P(w_1, ..., w_T) = P(w_1)P(w_2|w_1)P(w_3|w_1, w_2) ... P(w_T|w_1, ..., w_T-1)
[단어 배열 순서가 w_1 → w_2 → w_3 → ...로 나타날 확률] = [w_1이 첫째로 나올 확률] x [w_1이 발생했을 때 다음 단어로 w_2가 나올 확률] x [w_1, w_2가 발생했을 때 다음 단어로 w_3가 나올 확률] x ...
n-gram 개념 적용
텍스트에서 n개의 글자/단어의 연속된 시퀀스를 가리키며, 이 때 n은 n-gram의 길이가 된다.
n-gram 모델에서는 단어의 순서 배열을 어떻게 확률로 표현할 것인가?
n-gram 언어 모델에서는 말뭉치를 쪼개는 단위인 '토큰' 기준으로 문장을 쪼개고, 하나의 토큰에 몇 개의 글자/단어를 포함시키느냐에 따라 n에 해당되는 숫자가 달라진다.
하나의 토큰에 1개의 글자/단어만 포함시키면 1-gram(=unigram), 2개면 2-gram(=bigram), 3개면 3-gram(trigram) 모델이 완성된다.
n개의 단어를 기준으로 토큰화
Example The black cat eats a muffin. [unigram] The / black / cat / eats / a / muffin [bigram] The black / black cat / cat eats / eats a / a muffin [trigram] The black cat / black cat eats / cat eats a / eats a muffin
위의 예시와 같이, n값에 따라 문장을 쪼개는 토큰의 크기가 달라지고, 왼쪽에서 오른쪽의 순차적 방향으로 문장을 쪼갠다. 즉, 토큰을 생성하는 과정에서 앞선 (n-1)개의 단어 히스토리를 함께 고려하는 것이라 볼 수 있다.