워드 임베딩에서는 라벨이 매겨지지 않은 데이터셋을 사용한다. 즉, 모델이 학습하는 데 사용하는 데이터셋에는 정답이 따로 부여되지 않았으며 이에 따라 모델은 정답을 학습하는 것이 아니라는 뜻이다.
새로운 개념 아래에 유사성에 따라 수많은 데이터를 모으고, 데이터셋 내에 존재하는 유사한 단어를 파악하고, 여러 단어가 주어졌을 때 그 뒤에 나올, 혹은 그 사이에 나올 단어가 무엇인 지 예측해본다.
워드 임베딩(Word embeddings)
Word2Vec 특정 단어를 어떤 차원에서 벡터로 나타내는 것이다. 단순히 하나의 알고리즘을 의미하는 것이 아니라, 워드 임베딩을 학습할 때 쓰이는 특정 모델 아키텍쳐나 최적화 등을 통칭하는 말이다.
워드 임베딩은 Bow(Bag of Words)와 구별되는 몇 가지 특징을 지닌다. BoW에서는 여러 문제점이 존재했는데, 먼저 단어들이 주어졌을 때 그 순서를 알 수 없다는 점이다.
문제점 Example (1) doc 1: 개는 고양이를 따라간다. doc 2: 고양이는 개를 따라간다.
위의 두 문장을 이루는 단어들은 한 가방에 뒤엉킨 채로 존재할 것이다. 두 문장을 구별하는 것은 '개'와 '고양이'의 어순이다. BoW에선 그 순서를 알 수 없기 때문에 doc 1과 doc 2가 완전히 같은 문장이 될 가능성이 있다.
문제점 Example (2) (1) The teacher was angry. (2)The tutor was mad.
유사어를 판별하지 못한다. 위 두 문장은 거의 의미적으로 유사하다. 하지만 BoW는 유사어를 판별하지 못하여 'teacher'와 'tutor', 그리고 'angry'와 'mad'를 다른 단어로 취급해버리며, 결국 두 문장이 다른 문장이라 판단할 것이다.
간단하게 정리하면, 위와 같은 예시의 문제점을 해결하기 위한 방법이 워드 임베딩이다.
① 임베딩되어 있는 데이터셋에서 유사성을 갖는 데이터끼리는 가까이에 존재한다. 단어 'sad'와 'gloomy'를 2차원 공간에 임베딩한다고 할 때, 만약 'sad'가 [0.02, -0.02]로 2차원 공간에 나타내졌다고 하면, 'gloomy'는 이의 유사어에 해당하므로 비슷한 위치인 [0.01, -0.01] 정도로 2차원 공간에 존재할 것이다.
ex) 2D word embedding space
이처럼 워드 임베딩을 통해 역으로 특정 단어의 유사어 또한 얻을 수 있다.
② 임베딩을 사용하면 더 적은 파라미터로 모델을 학습시킬 수 있다. 연속하는 두 단어에 이어 나타날 단어를 예상하는 모델이 있다고 생각할 때, 먼저 입력값으로는 연속하는 두 단어에 대한 정보가 될 것이고, 출력은 그 다음에 이어서 등장할 단어와 관련한 정보일 것이다.
여러 방식 중 단어를 one-hot 인코딩 방식으로 표현하여 입력으로 넣는 대표적인 방법이 있다. 만약 데이터셋에 포함된 단어의 개수가 n개라고 한다면, n차원 공간에 각 단어를 one-hot 인코딩 할 수 있고 총 2n 길이의 벡터가 입력으로 들어가 그 다음에 이어서 나올 단어를 예측할 것이다. 입력의 크기가 2n인 것처럼 입력의 크기는 각 단어의 길이와는 무관하게 단어가 몇 차원에 임베딩 되었는 지만 중요하다.
만약 50차원의 단어 임베딩을 사용한다면 이때 입력값의 크기는 항상 100이 된다. 이 원리에 따라 더 적은 파라미터로 워드 임베딩을 보다 빠르게 학습시킬 수 있다.
오토인코더(Autoencoder)
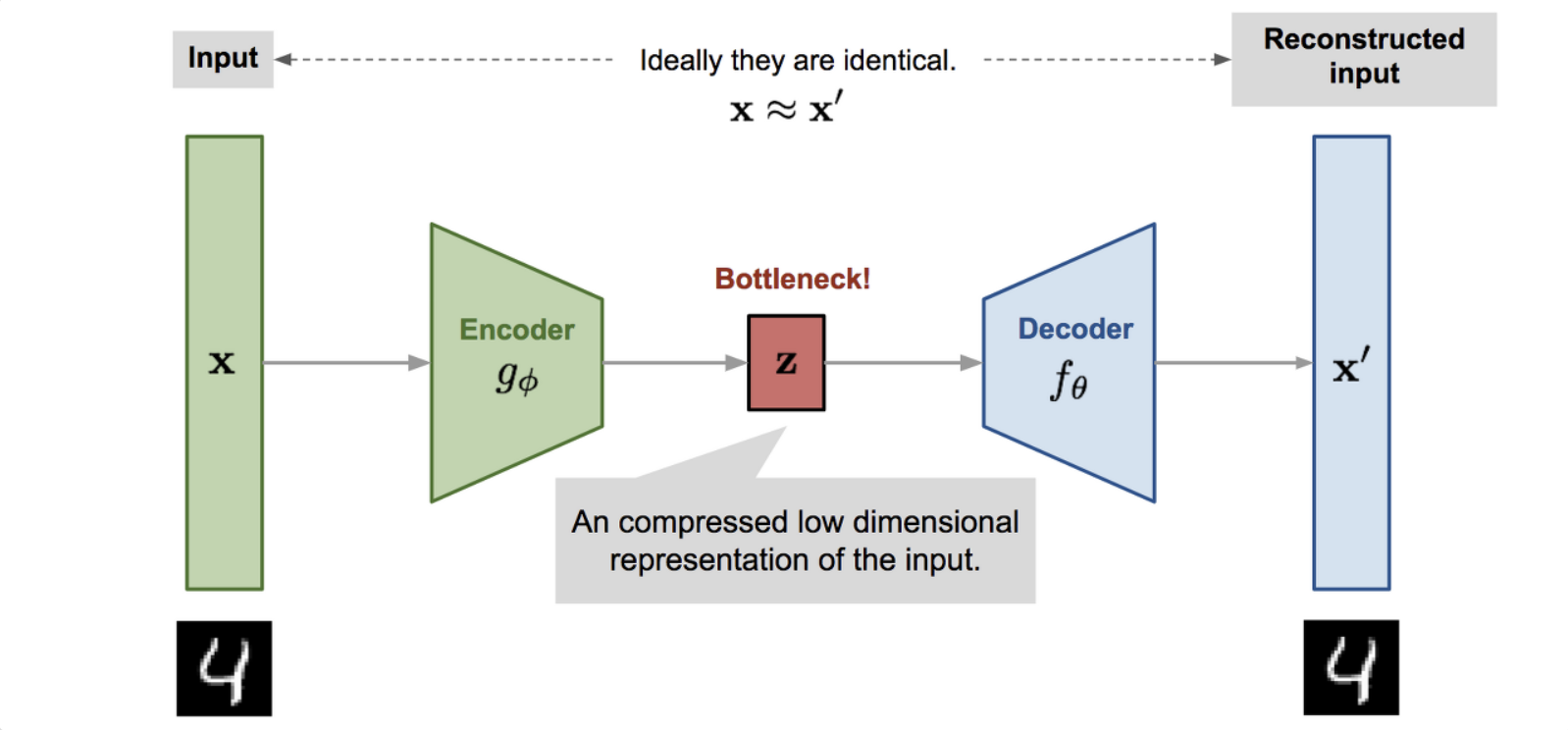
입력 데이터를 압축된 형태로 학습시킬 수 있도록 하는 신경망의 한 부분으로 오토인코더가 존재한다. 오토인코더는 데이터가 들어오면 이를 인코딩하여 압축된 형태(데이터의 차원 축소)로 나타내고 다시 디코더를 통해 데이터를 복원한다.
차원을 축소하는 과정을 거치는 이유는 데이터가 갖고 있는 특징 중 더 중요한 것을 골라내고 나머지를 지워내는 데에 있다. 이것이 성공한다면 자동으로 데이터 용량도 감소할 것이다.
오토 인코더 구조
인코더와 디코더가 동시에 작동하도록 하고 인코더가 데이터를 압축할 때 발생하는 손실을 최적화할 수 있는 방안을 찾아야 한다.
원래 입력한 데이터에서 오토인코더를 거친 데이터를 빼준다. MSE Cost를 손실함수로 하여 모델을 학습시킴으로써 오토인코더를 거친 데이터의 정확도를 높일 수 있다.
Word embeddings: 비지도 학습
많은 워드 임베딩 기술은 비지도학습에 기반을 둔 방식으로, 정답이 주어지지 않은 상황에서 연속적인 공간에 데이터셋의 데이터를 클러스터링한다(다수의 데이터가 특정 기준; 단어들이 모여 이루는 문맥 등에 따라 임베딩이 이루어지면서 여러 집단으로 나뉘는 현상). 이러한 비지도학습에서 사용되는 데이터셋은 데이터에 정답 여부를 표기하지 않아도 되기 때문에 값이 싸고, 단어가 갖는 유사성을 벡터로 나타내는 임베딩 작업에 유용하다.
Autoencoder: 자기 지도학습하는 모델 오토인코더는 입력된 데이터의 차원을 축소하는 작업을 행한다. 주어진 정답을 학습하는 것이 아니라 주어진 데이터를 학습에 용이하게 하기 위해 축소한 다음 다시 원래 데이터에 가깝게 복원하고자 한다. 결국 출력이 처음 입력된 데이터에 가까운 값일 수록 좋은 모델이고, 이는 오토인코더가 정답으로 입력 데이터를 사용한다는 뜻이다. 이러한 모델을 자기 지도학습을 하는 모델이라 한다.
워드 임베딩을 통한 모델 학습
One-hot 인코딩
하나의 데이터를 인코딩할 때 총 n개의 데이터가 존재한다면 n-bit로 이루어진 수로 표현하는 것으로, 하나의 비트만 1이 되고 나머지 bit는 모두 0으로 인코딩하는 암호화 방식이다.
1의 위치는 일반적으로 각 데이터가 데이터셋에 위치한 순서, 즉 인덱스로 정하며 단어가 임베딩 된 형태를 보고 이 단어가 전체 단어 집합에서 몇 번재에 위치하는 정보인 지 알 수 있다.
Example vocabulary에 6개의 단어가 있고 'people'이란 단어가 가지는 인덱스가 3이라고 한다면 'people'의 one-hot 인코딩은 다음과 같다. [0, 0, 0, 1, 0, 0]
One-hot 인코딩을 마치면 어떤 단어 조합이 주어졌을 때 그 문맥에 맞는 단어를 예측할 수 있게 된다.
다음은 주어진 단어로부터 타겟 단어를 예측하고자 할 때 사용할 다양한 모델이다.
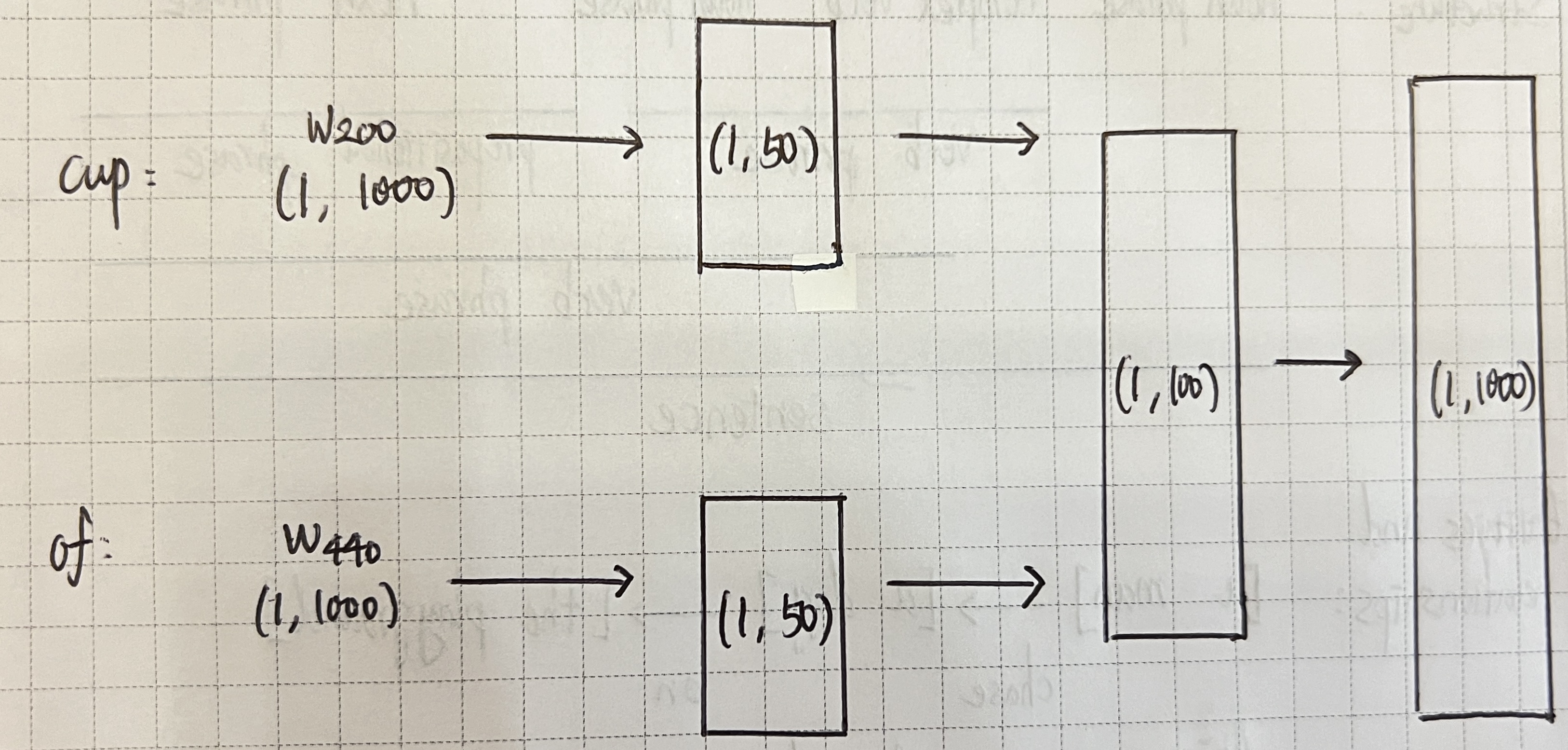
오토인코더 'cup'과 'of'란 단어가 주어졌고 이들 다음에 나올 단어, 즉 y_pred = 'coffee'를 얻고자 한다. 총 1000개의 단어가 있는 데이터셋이 있고, 각 단어는 (1, 1000) 크기의 One-hot 형태로 임베딩 되어 있다. ex) 오토인코더를 통한 단어 예측 오토인코더는 입력된 one-hot으로 인코딩된 단어의 차원을 축소시키고, 이를 합쳐 (1, 100) 크기의 형태로 만든 후 다시 원래 크기의 (1, 1000)의 데이터로 복원시킨다. 이 (1, 1000)의 데이터는 각 수를 0에서 1 사이의 확률값으로 정규화시켜주는 활성화 함수인 softmax 함수를 거쳐야 한다. 이 모델이 제대로 학습되었다면 출력 벡터는 'coffee'에 대응하는 단어 벡터여야 한다. 최종적으로 softmax를 거쳐 얻은 값인 y_pred = [0.01, 0.02, ..., 0.9, ..., 0.03, ...]이 출력일 때, 이 벡터에서 1에 근접한 0.9라는 값을 갖는 자리의 index에 대응하는 단어가 바로 'coffee'가 된다.
Skip-gram 중심 단어(input)가 주어지면 그 주위의 문맥어(output)를 추측해낼 수 있도록 하는 비지도학습이다.
'apple'이란 단어가 주어지면 그 주위 문맥을 형성할 수 있는 단어는 제한적이다. 데이터셋에 포함된 'juice', 'glass', 'of'의 단어가 문맥상 올 수 있는 데이터셋이 있다고 한다면, 이들 단어가 'apple'과 함께 등장할 확률은 높을 것이다. 즉, P(glass|apple), P(juice|apple), P(of|apple)은 큰 값을 가지지만 P(dolphin|apple)와 같은 확률은 작은 값일 것이다. 이처럼 중심 단어의 one-hot 벡터를 기준으로 하여 그 주위에 올 수 있는 문맥 단어가 갖는 one-hot 벡터를 얻어내는 과정이 skip-gram이다.
CBOW(Common Bag of Words) CBOW는 문맥어(input)가 주어지면 그 중간에 들어갈 단어인 target word(output)를 벡터 형태로 얻을 수 있는 학습 방식에 속한다. 만약 'juice', 'glass', 'of'가 주어진다면 그 사이에 올 수 있는 가장 가능성이 높은 단어는 'apple'이 되는 데이터셋이 있다 가정한다. ex) CBOW를 통한 단어 예측 원래 1000차원으로 one-hot 인코딩 된 각 단어 벡터는 오토인코더를 통과하며 그 차원이 50으로 줄었다. 이들을 합쳐 하나의 50차원 벡터를 얻고 여기에 모양이 (50, 1000)인 가중치 행렬을 곱해주어 원래의 차원인 1000으로 데이터를 복원한다. 마지막으로 softmax를 적용하여 각 벡터 성분을 확률로 바꾸면 출력된 1000차원의 단어 벡터가 가리키는 단어는 이들 사이에 들어갈 'apple'이라는 단어일 것이다.
의미론적(Semantic) 유사성 기반 인코딩
의미론적 유사성에 따라 임베딩을 통해 모델을 학습시키는 방법도 있다. 이는 단어 i가 등장할 때 그 주위 문맥어(context word)로 j가 등장한 횟수를 표현한 개념을 통해 임베딩을 만드는 방식을 바탕으로 한다.
아래의 행렬을 '문맥 행렬(context matrix)'이라고 부르고 행에 오는 단어는 중심어(center word), 열에 대응하는 단어는 문맥어(context word)에 해당한다.
cute
little
scary
dragon
0
1
8
kitten
28
42
4
puppy
30
39
0
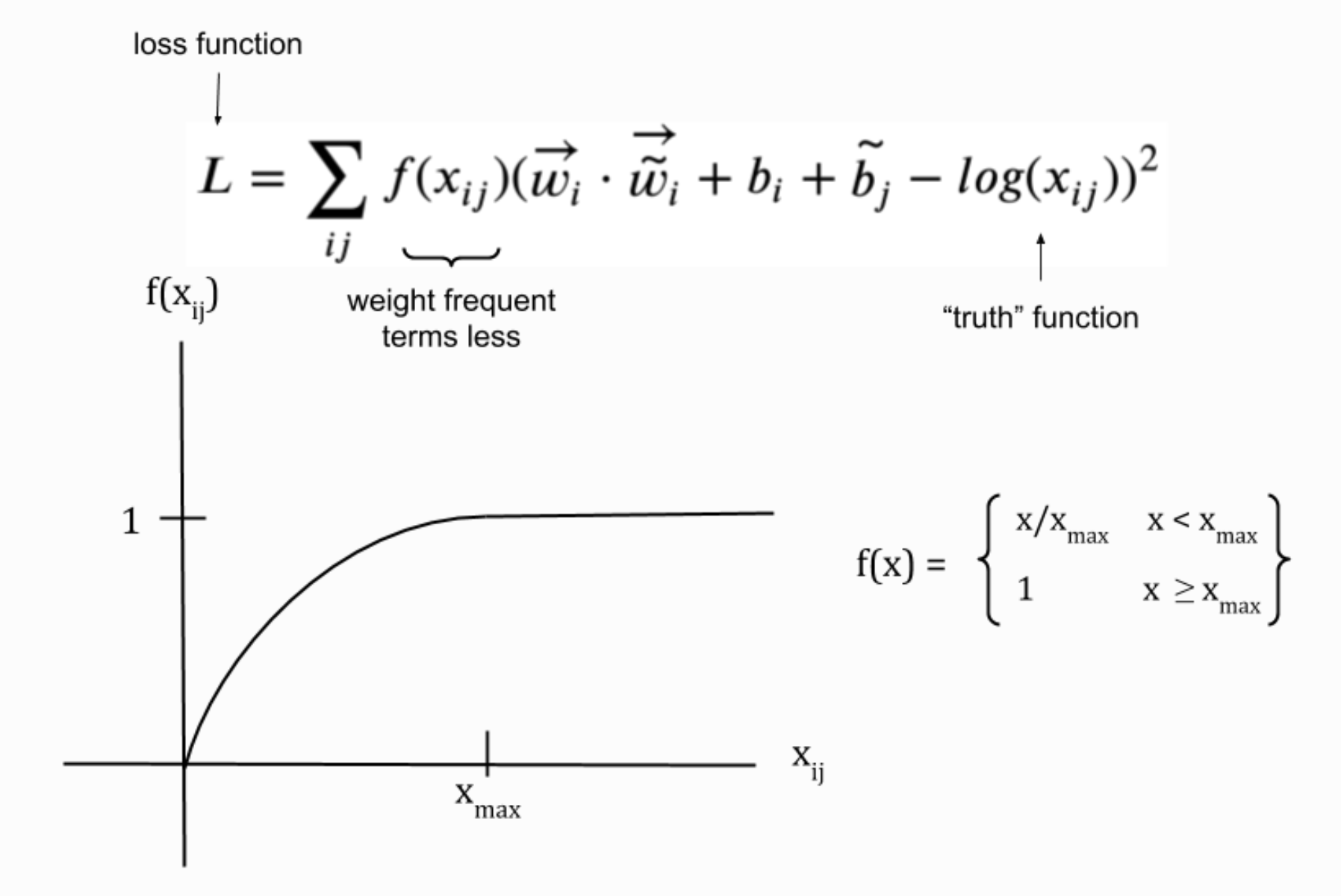
이 때의 손실함수는 다음과 같다.
x_max란 임의로 설정할 수 있는 값이다. 함수 f(x)는 가중치의 개념이다. 이 x_max보다 적은 횟수에 해당하는 x_ij에는 적은 가중치가 부과되도록 하는 역할을 하고, x_ij가 너무 큰 값일 때를 대비해 그 한계를 x_max로 지정해서 f(x) = 1의 일정한 가중치를 부여한다.